|

 导读 在现在快速发展的数据分析畛域,智能分析平台正阅历从传统 BI 到敏捷分析,再到智能分析的鼎新。随着挪动互联网的兴起和大谈话模子的出现,数据分析变得更加普及,用户可以通过天然谈话与系统进行互动,获取所需数据。关联词,即使在敏捷分析阶段,仍然存在一定的学习本钱。大谈话模子的引入为数据分析带来了新的机遇,它不仅普及了谈话领路和生成能力,还使得逻辑推理与器具使用变得更加高效。通过对用户天然谈话指示的领路和迂曲,智能分析平台能够完毕更直不雅的数据查询和分析过程,为用户提供更为方便的就业。本文将共享腾讯基于 LLM 的智能数据分析平台 OlaChat 的落地实践。 主要内容包括以下几大部分:1. 从传统 BI 到智能 BI 2. LLM 时间智能 BI 的新可能 3. 腾讯 OlaChat 智能 BI 平台落地实践 4. 问答短处 共享嘉宾|谭云志 腾讯 高档联系员 裁剪整理|陈念念永 内容校对|李瑶 出品社区|DataFun 01从传统 BI 到智能 BI 随着大谈话模子(Large Language Models, LLMs)的快速发展,智能分析在生意智能(Business Intelligence, BI)畛域的影响日益显耀。本节将探讨从传统 BI 到智能 BI 的过度过程,分析这一瞥型所带来的新机遇与挑战。
1. 传统 BI 的局限性 传统的生意智能体系频繁是基于一种从上至下的模式,业务崇拜东说念主提倡需求,开发东说念主员进行数据索要和分析,最终经过一段时刻的开发后,将铁心响应给业务方。这种过程不仅效能低下,还存在较大的相通本钱,导致决策的蔓延。用户常常需要恭候一周致使更长的时刻,才能赢得所需的数据分析铁心。2. 挪动互联网时间的敏捷分析随着挪动互联网的崛起,数据的丰富性和复杂性不断增多,商场对数据分析的需求也在发生变化。敏捷分析应时而生,它旨在使更多的用户能够方便地获取数据并进行自助分析。通过粗拙的拖拽操作,用户可以减弱进行数据探索。关联词,调研走漏,即等于这种粗拙的操作,对某些用户来说依然存在较高的学习本钱。比如,用户在进行环比狡计或其他复杂操作时,仍需掌持关联功能的使用方法,存在一定的门槛。3. 智能 BI 的初步探索 到了 2019 年,智能分析的构想开动萌芽。天然大谈话模子尚未全面普及,但一些在天然谈话处理畛域推崇邃密的模子仍是出现。这一时期,业界开动祥和若何让更多的用户能够减弱进行数据分析,场地是将每个东说念主都鼎新为“数据分析师”。智能分析的想法迟缓变成,清苦于于简化数据分析过程,镌汰用户的本事门槛。现如今,随着大谈话模子的普及,智能BI 迎来了新的发展机遇。大谈话模子不仅能够处理复杂的数据查询,还能通过天然谈话与用户进行交互,使得数据分析变得更加直不雅和东说念主性化。用户只需用天然谈话面孔他们的需求,系统便能自动生成相应的分析铁心,这大大提高了分析的效能和准确性。02LLM 时间智能 BI 的新可能 大谈话模子(Large Language Models, LLMs)的发展历程展现了天然谈话处理(NaturalLanguage Processing, NLP)畛域的显耀跳动。接下来将梳理大谈话模子的发展头绪,并探讨其对数据智能分析所带来的新机遇。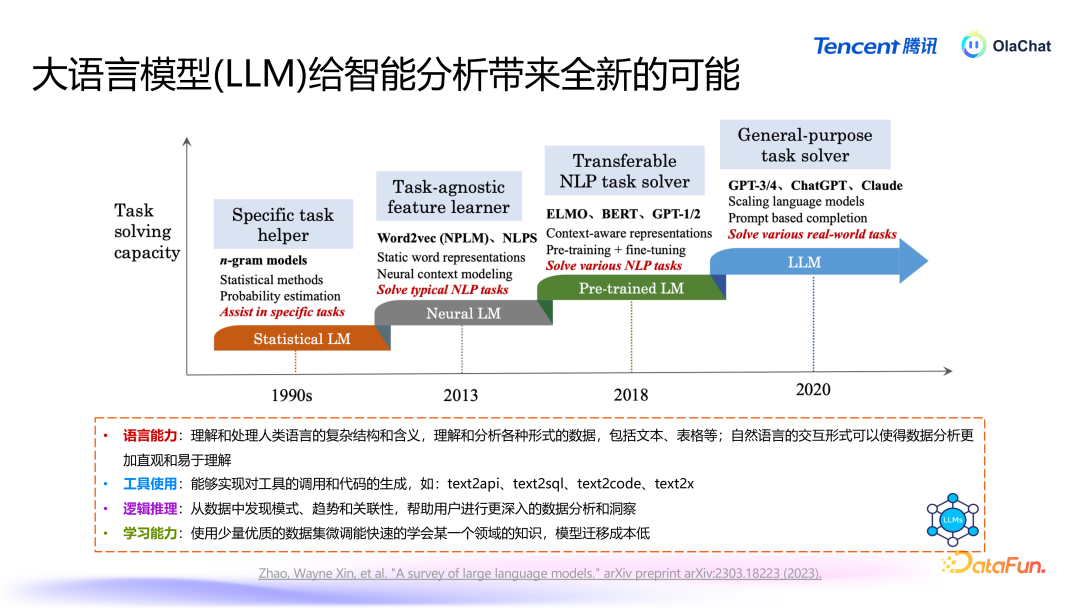
1. 大谈话模子的发展头绪 (1)初期阶段:基于概率的谈话模子天然谈话处理的早期阶段主要依赖于概率模子,如条目当场场(Conditional Random Fields, CRF)和马尔可夫模子。这些模子基于历史数据,通过词袋模子(N-gram Model)来狡计词语出现的概率。此时,谈话模子的能力相对有限,主要侧重于基于历史词语的概率议论。(2)神经汇集时间的崛起2013 年,谷歌发布了一项具有里程碑真谛的方法 word2vec,标识着基于神经汇集的谈话模子时间的到来。在这一阶段,诟谇期回首汇集(Long Short-Term Memory, LSTM)等模子开动得到世俗应用。神经汇集的引入大大提高了谈话模子的性能,增强了其对高下文的领路能力。(3)Transformer 模子的兴起2017 年,Google 发布了 Transformer 架构,由此在 2018 年前后出现了一系列基于此的模子,如 BERT、GPT1/2 等。相较于之前的模子,BERT 和 GPT1/2 模子的参数目显耀增多,达到千万、数亿限制。这些模子通过在多半语料上进行协调磨练,可以快速顺应不同任务,展现出广泛的谈话领路能力。(4)现时的万亿参数时间随着 GPT-3 和后续版块的推出,谈话模子的参数目达到了千亿、万亿级别。这使得一个模子能够同期在多个任务上达到较好的效能,镌汰了对多个模子的依赖。在这一阶段,谈话模子在文本生成、领路和逻辑推理等方面的能力都得到了极大的普及。2. 大谈话模子对数据智能分析的影响 大谈话模子为数据智能分析带来了以下四个方面的立异:谈话能力:大谈话模子在谈话领路和生成方面的能力相配广泛。它能够有用解读文本和表格数据背后的含义,使得数据分析变得更加直不雅、易于领路。通过天然谈话交互,用户可以更减弱地进行数据分析,而不需要深切掌持复杂的器具和本事。器具使用:大谈话模子能够将用户的指示迂曲为器具调用或代码生成。举例,用户可以通过粗拙的天然谈话请求,生成相应的 API 调用或代码。这种能力显耀提高了数据分析的效能,镌汰了本事门槛。逻辑推理能力:尽管大谈话模子的逻辑推理能力相对有限,但它在模式识别、趋势分析和关联性发现方面仍然推崇出色。这为数据智能分析提供了有劲解救,使得用户能够从数据中索要有价值的细察。学习能力:在早期,磨练一个模子以顺应特定任务频繁需要多半的数据。关联词,收成于大谈话模子的“高下文体习”(In-contextLearning)能力,用户不需要进行模子磨练也能在一些任务上取得可以的效能。即使需要微调,用户也可以通过较少的数据(仅需几千条)就能调治模子以心仪特定需求,这种顺应性使得大谈话模子在各样任务中的应用变得更加天真。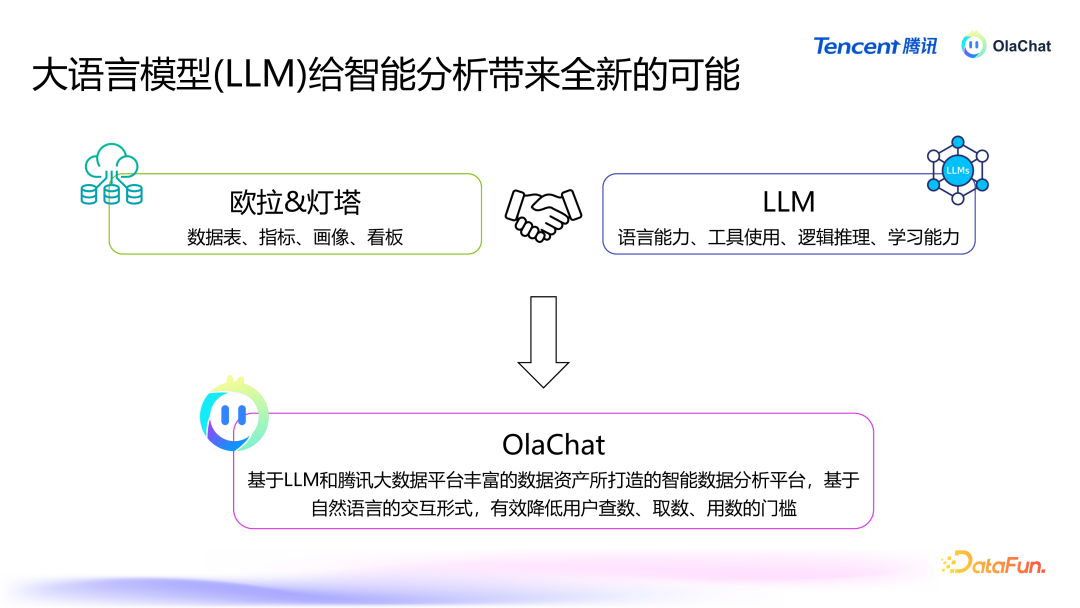
基于腾讯PCG 大数据平台部钞票经管平台“Ola”和数据分析平台“灯塔”丰富的元数据和用户行为日记,讨好大谈话模子的能力,咱们构建了 OlaChat 这一智能数据分析平台。OlaChat 能够提供高效和智能的数据分析就业,心仪用户问数、东说念主群细察、NL2SQL 等需求,有用镌汰了查数、取数、用数的门槛。接下来将凝视先容 OlaChat 平台落地实践。03腾讯 OlaChat 智能 BI 平台落地实践 OlaChat 智能数据分析平台主要场地是通过天然谈话交互,为用户提供通顺的数据分析体验。系统的中枢模块包括多任务对话系统、任务编排引擎、繁密的 AI 器具以及底层的全球就业能力。以下是 OlaChat 的短处功能与本事架构的深切解析。1. OlaChat 短处能力 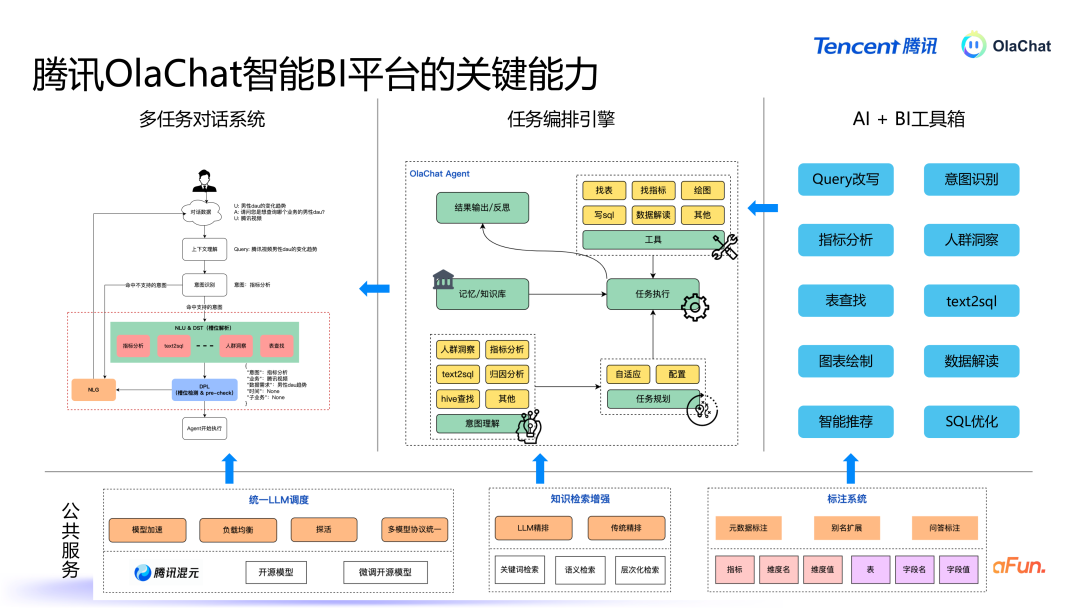
多轮对话系统:用户与 OlaChat 交互的第一进口是一个多任务对话系统,近似于智能助手,用户通过天然谈话与系统进行交互,系统需要具备领路用户意图并履行关联任务的能力。任务编排与履行:系统领路用户意图后,计算出履行任务所需的才略,并按表率调用关联器具和数据。AI+BI 器具箱:包括 Query 改写、text2SQL、办法分析等器具,这些器具通过不同的组合可以完毕不同的能力,从而处置不同的任务。全球就业:底层由一些全球就业来救援关联能力,主要包括三个部分:协调 LLM 退换(包括腾讯的混元模子,以过头他一些微调过的模子),系统斥地了协调的模子退换机制,把柄不同任务自动遴荐合适的谈话模子,并进行负载平衡和模子加快,针对不同模子输入输出的景色各别,系统通过全球就业屏蔽这些各别,提供一致的交互接口。常识检索增强:提供了检索元数据的功能。标注系统:在数据分析过程中需要处理多半与特定畛域关联的数据,因此引入了标注系统,可以对自界说数据和办法进行标注,用于增广泛谈话模子的畛域领路能力。接下来将具体先容其中一些能力。2. 多任务对话系统 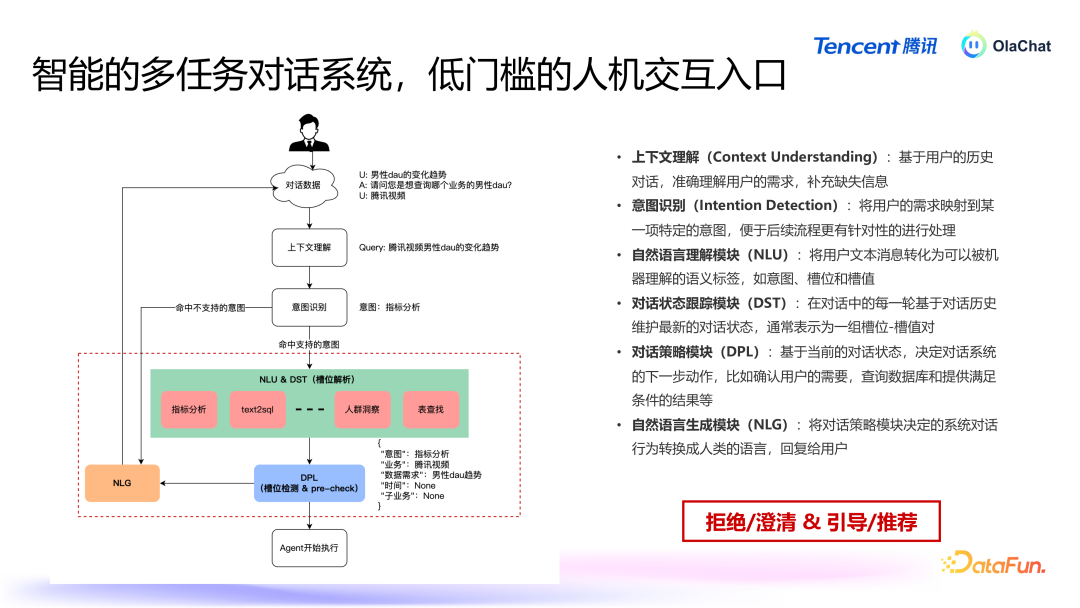
多任务对话系统提供的基础功能为拒却/明白,以及指示/保举。系统具备的短处能力包括:高下文领路:不断追踪高下文,基于用户的历史对话,准确领路用户的需求,补充缺失信息。意图识别:基于高下文领路,进行意图识别,将用户需求传到对应的 Agent。天然谈话领路模块(NLU):将用户文本音书迂曲为可以被机器领路的语义标签。对话景况追踪模块(DST):在对话中的每一轮基于对话历史看重最新的对话景况,频繁暗意为一组槽位-槽值对。对话战略模块(DPL):基于现时的对话景况,决定对话系统的下一步手脚。天然谈话生成模块(NLG):将对话战略模块决定的系统对话行为篡改为东说念主类语音,修起给用户。3. 元数据检索增强 在数据分析中,元数据的检索是一个短处才略,尤其当数据呈现结构化姿色时,传统的基于非结构化天然谈话的检索方法无法饱和适用。腾讯的智能分析平台通过增强元数据检索能力,处置了结构化数据中的多档次、复杂性问题,为用户提供更精确的分析解救。
结构化数据,比如表和办法,每个表有表名、字段,办法下有维度(如年岁、性别等),这些数据有档次性和明确的结构。这种档次结构不同于非结构化文本,弗成粗拙地通过天然谈话的检索增强方法来处理。传统的天然谈话检索主要基于 embedding(镶嵌向量)本事,将文天职块后,通过雷同度匹配来检索关联信息。关联词,结构化数据并不治服天然谈话的逻辑,导致传统方法难以平直应用。通用RAG 在处置元数据检索增强任务时存在一定的不适用性,主要因为:元数据是按特定的结构、档次组织的。办法、字段、维度的组合莫得固定的前后表率或天然谈话中的常见章程。如天然谈话中“中国的都门是“,后头随着的简略率会是“北京”,关联词元数据并不得当谈话模子的基本假定。特定修遁辞很遑急,某些特定的字段或维度往往具相关键性真谛,比如“有用播放次数”和“付费播放次数”暗意的是天渊之别的办法,这种各别无法通过传统的检索方式精确捕捉。字段名可以很短,这就要求检索方法能准确地拿获用户问题中的短处信息。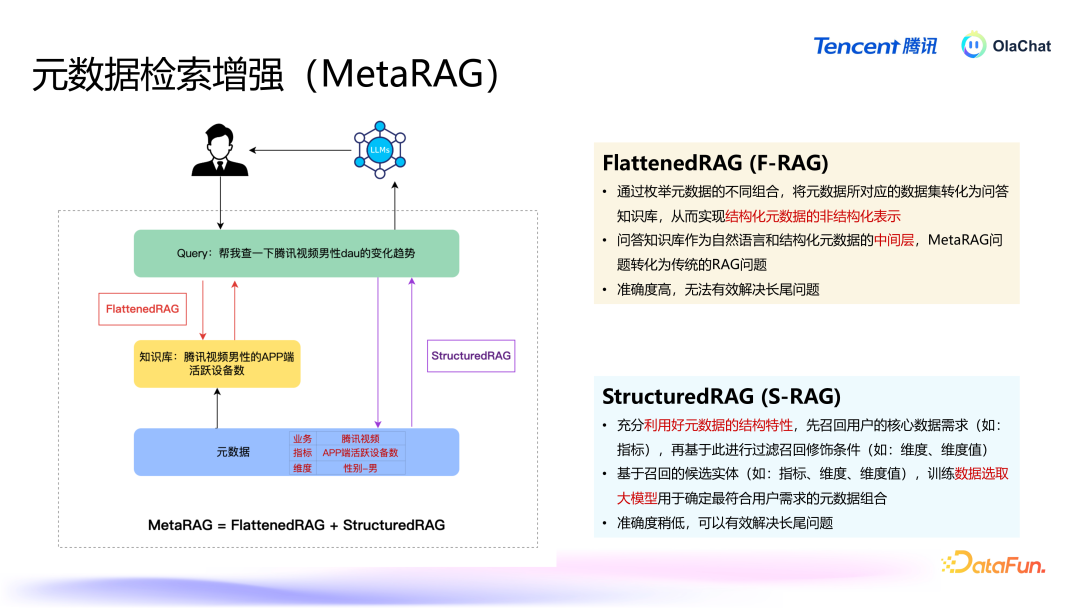
咱们有两种有瞎想,分别从两个角度来处置元数据检索增强的问题。第一种有瞎想是 FlattenedRAG,在已有元数据基础上进行组合,将结构化的元数据变为非结构化的天然谈话,当经受到用户问题后,进行检索、排序,找到与常识库中一致的数据。第二种有瞎想是 StructuredRAG,充分诈骗好元数据的结构化信息,优先检索出最中枢的元素,再围绕这些中枢元素进行二次检索,找到所需的数据。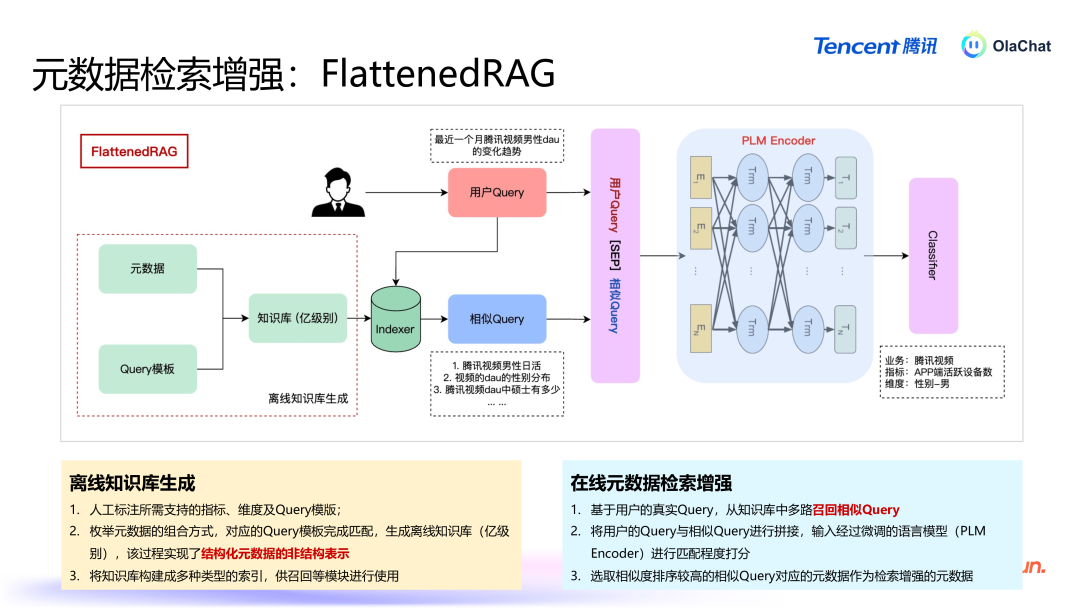
FlattenedRAG 的具体过程如下:元数据打平:将数据表、字段、办法等信息组合成近似于问答式的天然谈话。举例,办法为“活跃用户数”、维度为“男性”的查询组合可能会被打平为:“腾讯视频男性活跃用户数有若干?”。基于常识库进行检索:当用户提倡问题后,系统会从打平后的常识库中进行检索,找出与用户问题雷同的文本。排序和匹配:系统通过预磨练的分类模子对检索铁心进行排序,最终遴荐出最关联的谜底复返给用户。这种方法的中枢在于将结构化信息迂曲为非结构化文本,从而使得传统的天然谈话检索本事可以平直应用。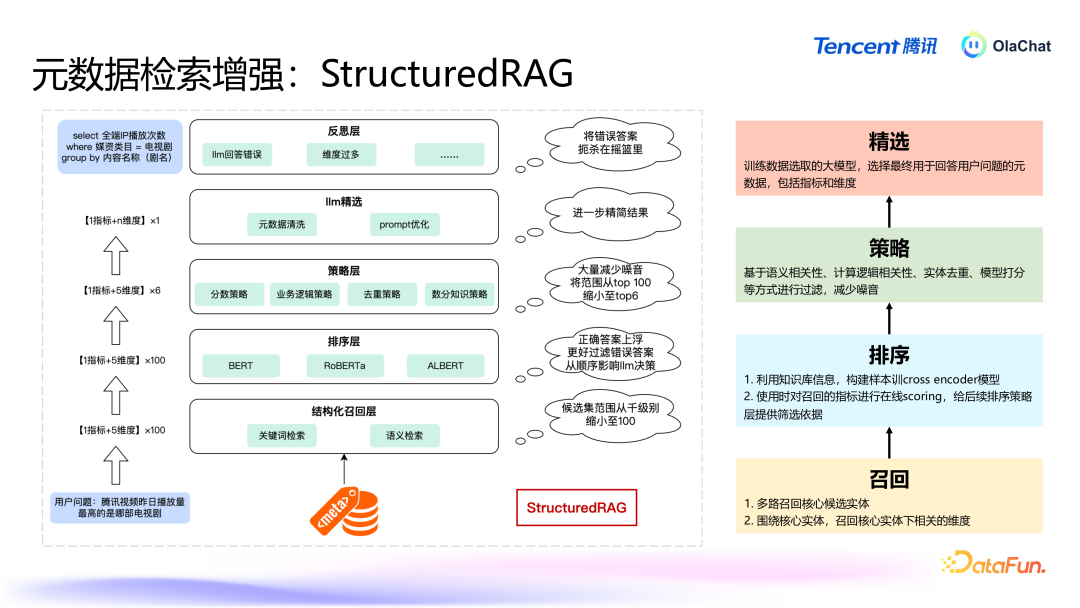
StructuredRAG 的主要过程如下:中枢元素的检索:当用户提倡问题时,系统当先会诈骗结构化信息的档次性,优先检索出最遑急的元素,如办法、维度等。举例,在用户究诘“腾讯视频的男性活跃用户有若干”时,系统会当先细目“活跃用户数”这个短处办法。围绕中枢元素的进一步检索:在找到中枢元素后,系统会进行二次检索,匹配用户的问题和中枢元素的其他关联信息,比如在上头的例子中会二次检索和“男性”雷同的多个维度。复返铁心:系统把柄中枢元素的检索铁心,再讨好进一步的二次搜索,临了经过一次排序之后给出最得当用户问题的谜底。两种方法各有优污点:买肤浅法:通过将结构化数据打平为非结构化文本,简化了复杂的数据结构,方便了天然谈话处理的应用。此方法的上风在于能够平直诈骗已有的天然谈话检索本事,操作绵薄,然而要是办法和维度的数目相配多时该方法可能会靠近组合爆炸的问题。结构化方法:充分诈骗了元数据的档次结构信息,能够在保持数据档次关系的同期提高检索的准确性。此方法在处理相配复杂且档次分明的数据时更加有用,尤其是包含多个维度的长尾问题。在试验应用中,这两种有瞎想各有其适用场景。举例,当办法和维度的数目相对有限时,买肤浅法可能更为高效;而在办法和维度组合较多的场景下,结构化方法规能够提供更目田的检索方式。这两种有瞎想的讨好,使得系统能够在不同场景下天真搪塞用户提倡的各式数据分析需求。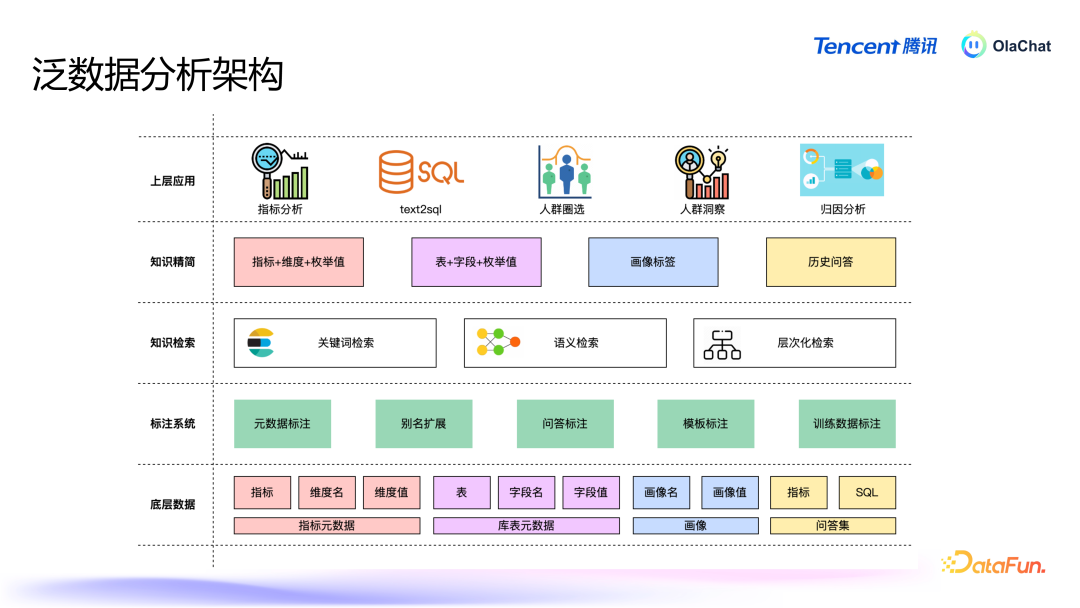
在泛数据分析架构中,底层是办法、库表等元数据,以及画像和历史问答集;这些数据投入标注系统后,会经过各式标注处理;之后是各式检索,包括短处词检索、语义检索等;检索后进行常识精简,继而为表层的办法分析、东说念主群圈选等各式应用提供解救。常识精简和常识检索就是由前边先容的元数据 RAG 完毕的。4. Text2SQL Text2SQL 信得过业务场景下存在着诸多问题:当先,数据隐讳与安全永恒是不可逾越的红线。举例,一些有名模子在使用公约中规则,企业要是月活跃用户数超越一定数目,就必须请求使用权限。这关于腾讯等大企业而言,意味着好多闭源和开源模子都不可用,因此必须开发自有模子以心仪业务需求。尽管大型谈话模子在本事上推崇广泛,但在业务领路方面却存在显耀不及。好多企业的数据质料较低且结构参差,模子很难准确领路。此外,模子常常劳作畛域常识,可能会产生“幻觉”。另外,模子的富厚性和准确率也存在不及。信得过情况下用户问法相配个性化,现存有瞎想的抗噪声能力不及(BIRD~70%),导致富厚性和准确率较差。企业在试验应用中常常难以获取到高质料数据,尤其是冷启动阶段,高质料的 query 到 SQL 的数据相配匮乏。基于上述问题,咱们最终选择了微调大模子+Agent 的有瞎想来完毕 Text2SQL。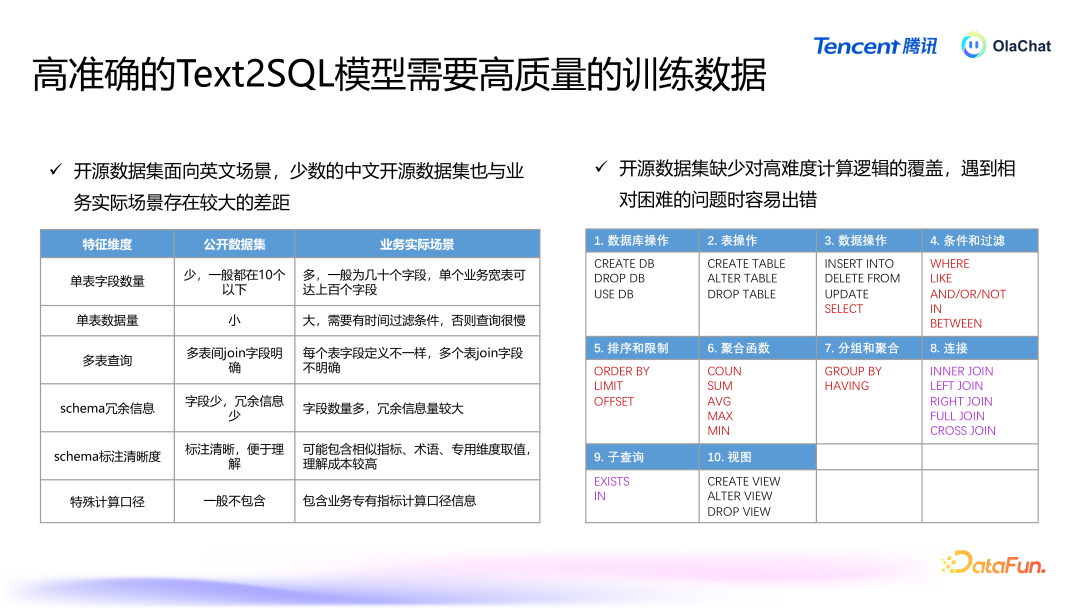
高质料的数据关于磨练高效的模子至关遑急。关联词,开源数据集大多面向英文场景,即使翻译成中语,结构也较为粗拙,频繁为单表,字段在 10 个以下,而试验业务场景中可能有上百个字段。这使得大型模子在处理这些数据时容易产生诬告或无法准确解读业务中的复杂逻辑。此外,开源数据集在操作符的使用上也比拟有限,常用的操作符较少,这进一步镌汰了模子在复杂任务上的推崇。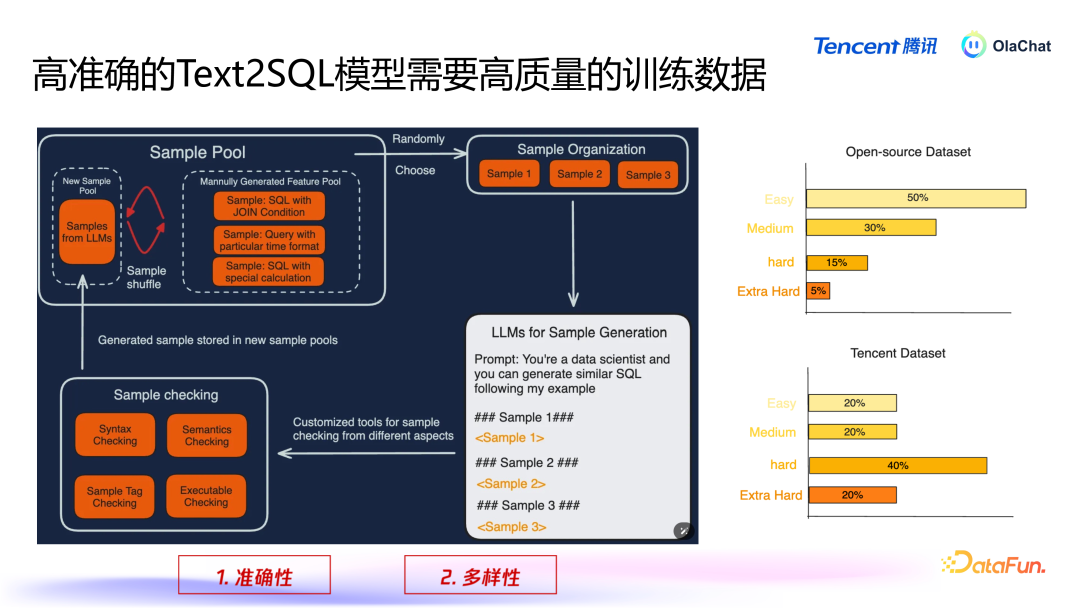
在咱们里面,仍是斥地了一套数据生成的逻辑过程。该过程主要包括以下几个才略:数据汇集与脱敏:当先,咱们会基于汇集到的腾讯里面数据,进行必要的脱敏处理,以确保用户隐讳和数据安全。当场选取数据:在经过脱敏处理后,咱们会从数据赓续当场遴荐一些样本,并将这些样本拼接成近似的辅导(prompt),然后输入到大型模子中。数据增强:诈骗这些样本,咱们会使用数据增强的方法,让模子基于已有样本生成新的样本,通过这种轮回不断丰富数据集。在数据增强过程中,有两个短处点需要颠倒祥和,即准确性和各样性。准确性:咱们必须确保大型模子生成的 SQL 是准确的。要是模子生成的 SQL 诞妄并被加入磨练集,就会导致模子性能下跌。因此,咱们瞎想了一套代码逻辑来搜检生成的 SQL 是否正确,当先这个 SQL 要能够履行,况兼与用户输入的查询语义相匹配,为此咱们使用一个挑升的模子来考证生成查询的语义正确性。各样性:咱们还需要确保数据的各样性,幸免模子生成多半雷同的数据。为此,咱们接管了一些雷同性检测的方法,剔除过于雷同的样本。此外,咱们会对生成的数据进行分类,确保各样别之间的平衡。要是某个类别的数据过多,咱们会减少该类别的生成;而关于数据较少的类别,则会要点生成更各样本,以普及数据集的合座准确性和各样性。在数据生成过程中,咱们将样本永别为不同的难度等第,包括粗拙(easy)、中等(medium)、繁难(hard)和颠倒繁难(extra hard)。咱们发现,开源数据集在繁难和颠倒繁难的数据生成上散布不均。因此,咱们颠倒要点生成这些繁难类型的数据,以弥补开源数据集的不及。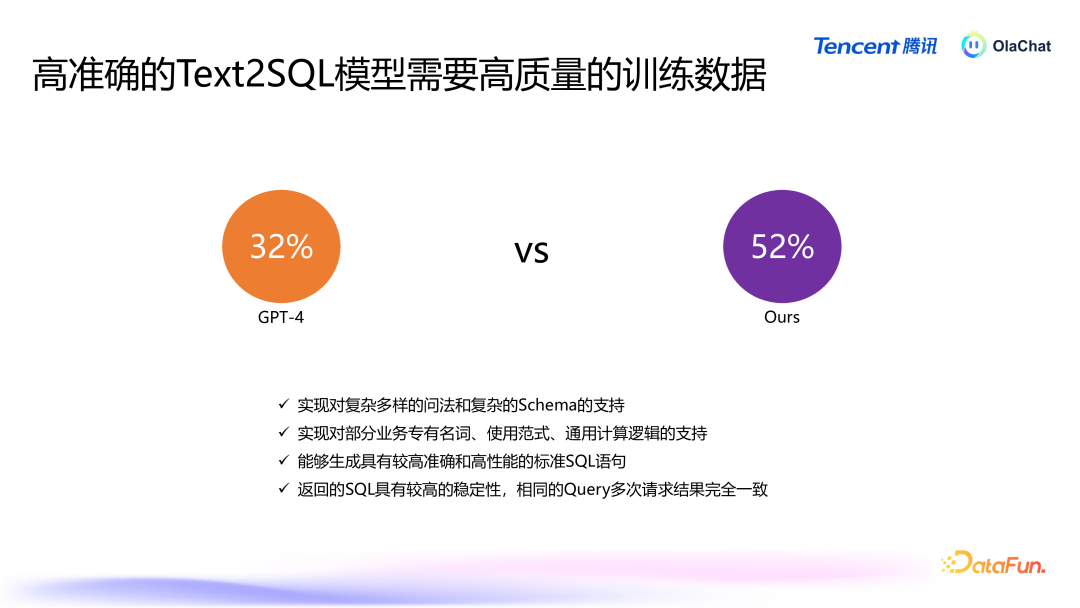
经过这么的数据增强与补充后,咱们对模子的推崇进行了评估。在信得过的业务数据集上,模子的准确率频繁较低,举例,GPT-4 的准确率为 32%,而咱们我方的模子可以达到 52%。除此以外,咱们磨练的模子还能完毕对复杂问法、复杂 Schema 和复杂狡计逻辑的解救,具有较好的富厚性。
咱们还发现,单独使用一个模子很难达到联想效能,原因如下:数据集隐敝不全:业务中的各式查询可能相配复杂,而咱们很难隐敝统统同学所编写的查询样本。谈话各样性与歧义:用户的谈话抒发多种各样,可能存在歧义和同义词,使得生成的查询难以心仪统统需求。杂音与信息搅扰:在数据赓续,存在一些杂音数据,这些信息会搅扰模子的磨练效能。在咱们的系统中,除了依赖于大型模子外,咱们还开发了一套智能体过程,旨在扶植大模子生成更高质料的 SQL。这个智能体的过程能够针对大模子在领路力、富厚性和准确率等方面的不及,实施相应的战略,以处置这些问题。减少冗余信息,引入扶植信息咱们意识到,将一张表的一起字段都传递给大型模子以供其领路并不现实。为了提高模子的准确性,咱们会当先进行字段的精选,过滤掉冗余字段,留住更关联的字段,从而使得模子在领路时更加赓续庸高效。适当融入传统模子/战略用户的问题表述往往较为拖拉,为了普及准确性,咱们可以通过模子对用户输入的问题进行标准化处理,并加入一些 fewshot 检索,从而提高模子的领路能力和生成准确性。对模子铁心进行后验优化生成的 SQL 可能并不老是能正确履行,咱们瞎想了一个后续纠错机制,诈骗大模子对生成的 SQL 进行审核,并进行必要的修改,同期可以进一步普及准确性。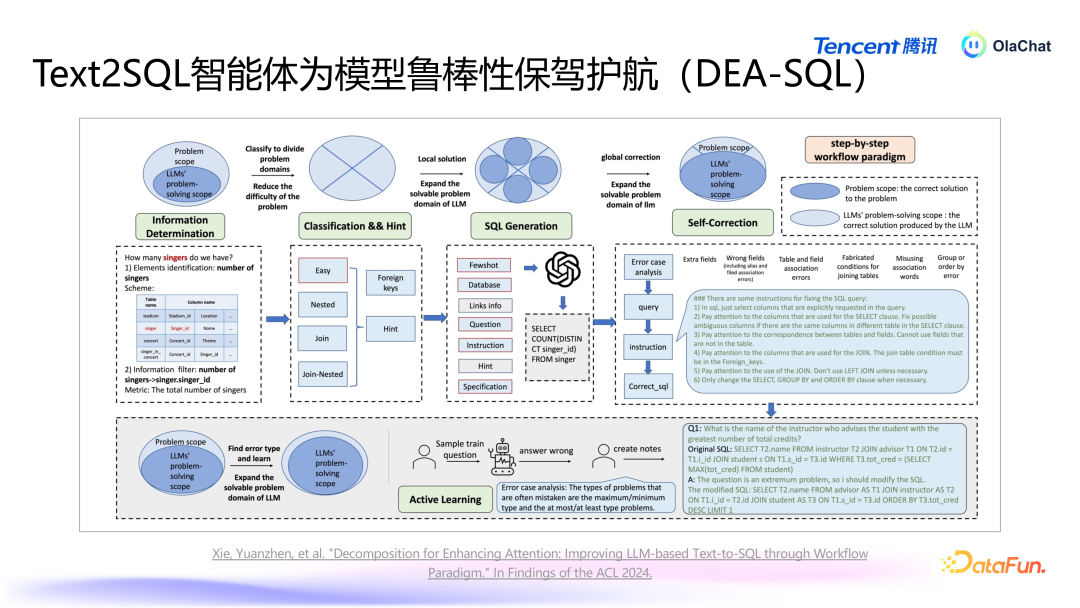
咱们将上述念念想整合成了一篇论文,探讨了若何通过信息精简、分类处理、针对性生成和自我纠错的过程来普及模子性能。在生成过程中,对不同复杂进程的查询选择不同处理方式,粗拙的查询与复杂的查询应有不同的生成战略。在生成时设定特定条目,确保生成查询得当履行要求。同期,实施自我纠错机制,让模子对我方生成的查询进行反念念与调治。此外,咱们还实施了主动学习(active learning)的战略,针对常见问题进行要点辅导。通过让模子专注于标准化问题,进一步提高模子的准确性。这一过程将智能体与大型模子相讨好,普及合座的准确率。5. Text2SQL 以外 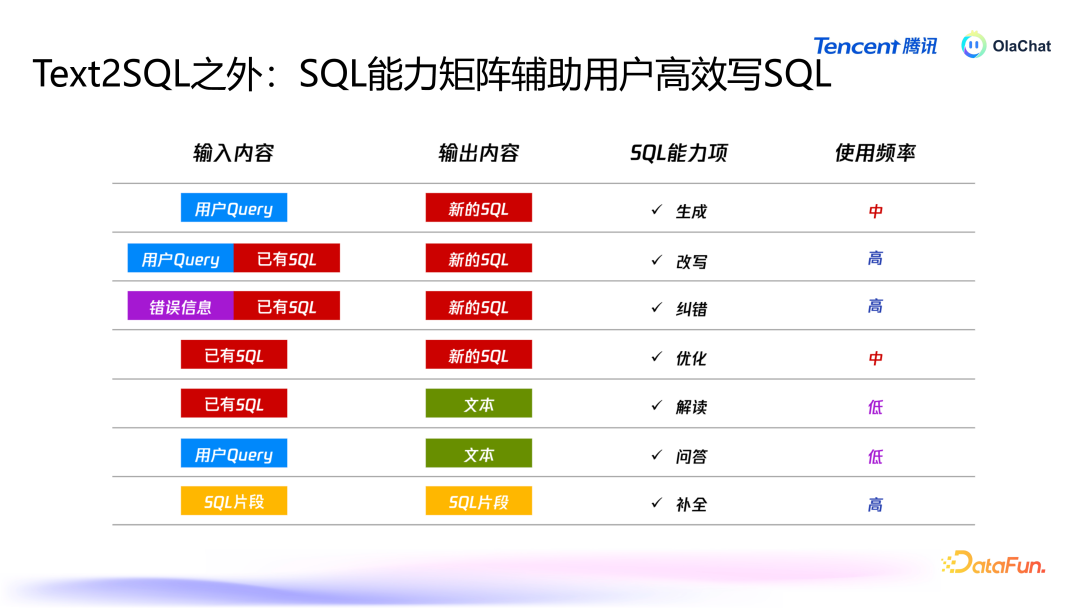
在进行智能分析时,用户的需求不仅限于 text2SQL,还会有改写、纠错、优化、解读、问答、补皆等多种需求。为了心仪用户多元化的需求,咱们在系统中构建了多个智能体,旨在扶植用户进行数据智能分析,普及效能。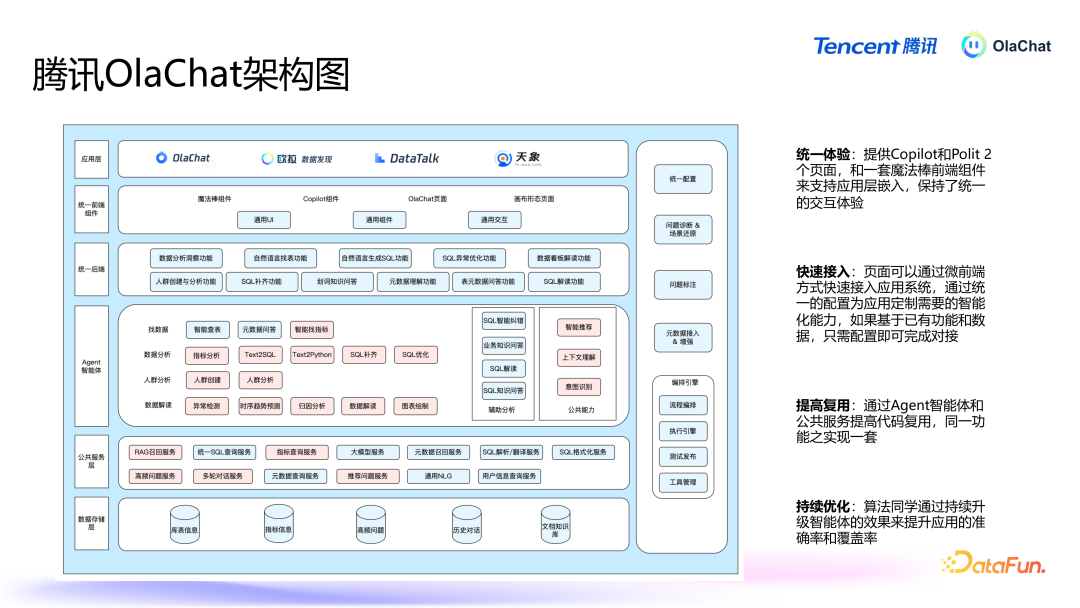
上图展示了 OlaChat 的合座架构,从下到上包括底层就业、中间全球就业、Agent、协调后端、协调前端,以及所解救的各式应用。不同模块互相投作,完毕通盘平台的协调体验,普及用户在数据分析过程中的效能与效能。04问答短处 Q1:取数时使用了多大的模子?A1:取数模子为 8B,相对较小,适当快速判断用户的查询。NL2SQL 接管的是 70B 的模子进行微调。Q2:若何保证归因的准确率?A2:归因的准确率依赖于归因器具。天然大模子推理能力强,但要讨好外部数据提高准确率。是以咱们的作念法为,基于归因器具拿到数据后,大模子崇拜在中间串联,作念一些谈话上的整理归纳,呈现给用户。Q3:SQL 纠错和 SQL 解读是否用了大模子?A3:SQL 纠错妥协读是用大模子完毕的,但仅用大模子的话准确率较低,因此需引入更多信息来优化。比如可以加入 SQL 顶用到的表的元数据,也可以将履行中的报错信息加入进去。是以弗成光用大模子,而是要把柄具体场景加入更多信息。Q4:平直生成 SQL 语句是否过于复杂?A4:平直生成 SQL 语句与基于语义层的简化方法各有上风,前者天真性高,后者适当对不熟习 SQL 的用户提供了有用的提效有瞎想。以上就是本次共享的内容,谢谢众人。
共享嘉宾 INTRODUCTION 谭云志 腾讯 高档联系员 腾讯 PCG 大数据平台部智能数据分析(ABI)平台算法崇拜东说念主,崇拜从 0 到 1 完毕 AI 算法在数据分析平台的落地,在大谈话模子、对话系统、text2sql 、保举系统等方面有较深切的联系。毕业于清华大学,先后履新于 LinkedIn、探探、腾讯,有近 10 年算法联系和算法居品落地训戒。
|